Introducción al Bootstrap
Curso: Análisis y tratamiento de datos con R
Introducción al Bootstrap
El bootstrap es un tipo de técnica de remuestreo de datos que permite resolver problemas relacionados con la estimación de intervalos de confianza o la prueba de significación estadística.
Este enfoque puede resultar de interés para los investigadores, no solo porque es menos restrictivo que el enfoque estadístico clásico, sino también porque es más general en su formulación y más simple de comprender en lo referente al procedimiento básico que subyace al método. En lugar de fórmulas o modelos matemáticos abstractos, el bootstrap simplemente requiere un ordenador capaz de simular un proceso de muestreo aleatorio de los datos. Sin embargo, y debido quizás a la escasa difusión de la técnica, los investigadores aún no han incorporado el bootstrap al repertorio habitual de herramientas de análisis de datos.
Las computadoras modernas han hecho posible ciertas formas de manipulación y análisis de datos antes inconcebibles. La visualización dinámica de datos, las técnicas de minería, la simulación y los métodos de remuestreo son algunos ejemplos de enfoques que, apoyados en las capacidades de los ordenadores modernos, han enriquecido el trabajo de exploración y análisis estadístico de datos. La relación entre ordenadores y análisis de datos es patente para el caso de las llamadas técnicas de remuestreo de datos ("data resampling""), entre las que encontramos el Jacknife, los test de aleatorización y permutación, la validación cruzada y el bootstrap.
Origen
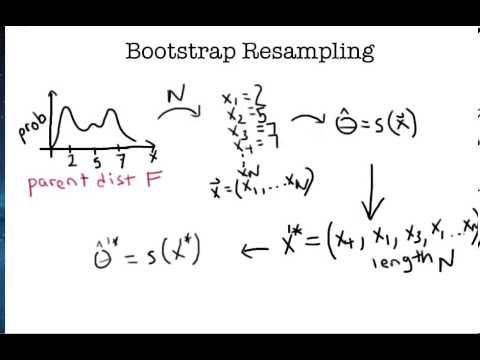
El bootstrap como método fue conceptualizado y descrito sistemáticamente por Efron (1979) y Tibshirani (1993), aunque se ha señalado que algunas ideas básicas relacionadas con este método pueden encontrarse en trabajos de autores previos. Se trata más que de una técnica o modelo específico, de un método general a partir del cual pueden cubrirse diferentes objetivos de análisis de datos, incluyendo la estimación de intervalos de confianza (IC) o el Test de significación estadística. En esencia, veremos que el método permite aproximar la distribución de muestreo de un estadístico y de sus propiedades mediante un procedimiento muy simple: Crear un gran número de muestras con reposición de los datos observados. Recordemos que la distribución de muestreo de un estadístico es clave a la hora de realizar tareas de inferencia estadística.
Remuestreo
La denominación de remuestreo se debe a que los métodos se basan, esencialmente, en la extracción de un gran número de muestras repetidas de los propios datos, y sobre esta base se realizan posteriormente descripciones e inferencias estadísticas. Se trata pues, de una estrategia general para resolver problemas de probabilidad y estadística aplicada, dentro del cual se pueden diferenciarse algunos métodos o procedimientos más específicos, entre los cuales el bootstrap resulta el más estudiado y extendido.
Datos
El siguiente archivo contiene la edad de un grupo de sujetos de interés.
Información
Escuela Politécnica Nacional, Edificio Administrativo, Octavo Piso